
")
Digitalization probably isn’t the first thing that comes to mind when you think about concrete. But Thomas Concrete Group recognized that digital transformation through IoT enablement would be an important step to improve customer experience, and the company’s ability to scale. As we learned over the course of our recent undertaking, the nuances of IoT require a careful approach when assembling an IoT data stack that’s truly built for IoT data.
If backed by the right data-layer strategy, digitalization and IoT can help industrial organizations optimize their supply chains, more quickly add new services, and drive more value based on their existing data. To assess the advantages IoT can deliver, industrial businesses should look at crucial segments of their supply chains to identify where information is most critical, and how digital access to that information might improve either operations or customer experiences.
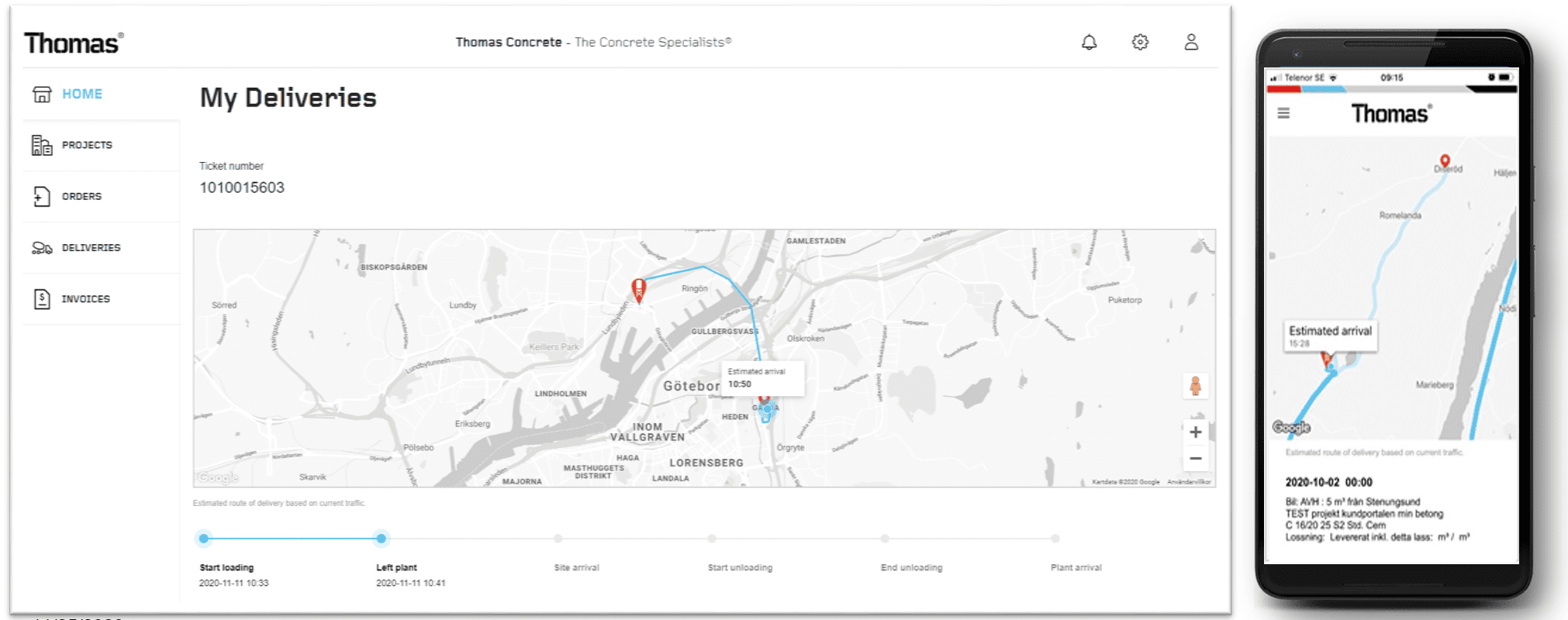
For our customers, the timing of deliveries of concrete to construction sites is crucial. Before, customers needed to call our plants to ask about truck locations and estimated arrival times to get this information – which they did quite frequently. So we recognized that real-time tracking of concrete deliveries was a good reason to implement an IoT strategy.

By making the GPS positions and ETA data of concrete trucks available to customers digitally – through an interface displaying truck locations on Google Maps – they could add more precision to their own operations. Customers would no longer need to call us for delivery information, because they’d have all the information at their fingertips, on their computers or mobile phones.
We also recognized a second opportunity for improving the customer experience by introducing real-time monitoring of the concrete curing process – to know and understand the strength of the concrete, and when it is ready for use. This meant introducing IoT sensors into the mix. Customers can now monitor the curing data online, and know exactly when concrete has properly cured – so they can proceed with construction without delay, saving time and money on projects.
To determine the industrial IoT data stack to support these twin workloads, the business set out to use Microsoft Azure. We recognized the advantages of leveraging the Azure IoT Hub to manage our IoT infrastructure, as well as Azure DevOps to enable automated CI/CD pipelines and programmatic deployments of applications and services. We then laid out the principal data stack requirements of our two industrial IoT use cases.
We vetted appropriate data technologies to make the vision a reality. Needless to say, there are a lot of databases on the market. Businesses should conduct thorough, in-depth investigations on how the strengths and weaknesses of available databases intersect with their own business requirements. The wrong choice can be fatal to the success of an IoT project.
In weighing-up the pros and cons – to determine whether we’d use a relational database, a document-based database, BLOBs, or some other approach to storing our vast amount of industrial IoT data points – we started from the best practice of considering the type of data we’d actually need to ingest. In our case, we were working with JSON data from sensors – a semi-structured data type most appropriate for a non-relational time-series database.
We also quickly realized our two use cases had fundamentally different requirements and characteristics. Real-time truck location tracking requires high ingestion performance. Some big data streaming architectures are better suited to use cases where latency in data arriving to the database is acceptable. But we couldn’t have that. High data ingestion performance – handling high read and write volumes with no delays – was essential to ingest and serve the data from our trucks in the field.
In contrast, our concrete curing use case called for high resiliency, requiring ingestion of temperature data from industrial IoT sensors and curing calculations as the concrete hardens over days and weeks. For our solution to deliver value to customers, it needed each and every one of those data points to determine the completion of the curing process very precisely.
As well, worksites can often be situated in remote locations – which requires offline IoT data storage (by remotely provisioning edge modules to store sensor data on industrial IoT devices). Adding to the complexity, our use cases are global, demanding scalability and placing further limits on which databases were suitable.
As Azure Kubernetes Service is extensively utilized for container-orchestration, we also required a database with the ability to run in a highly available (HA) configuration when run in Kubernetes.
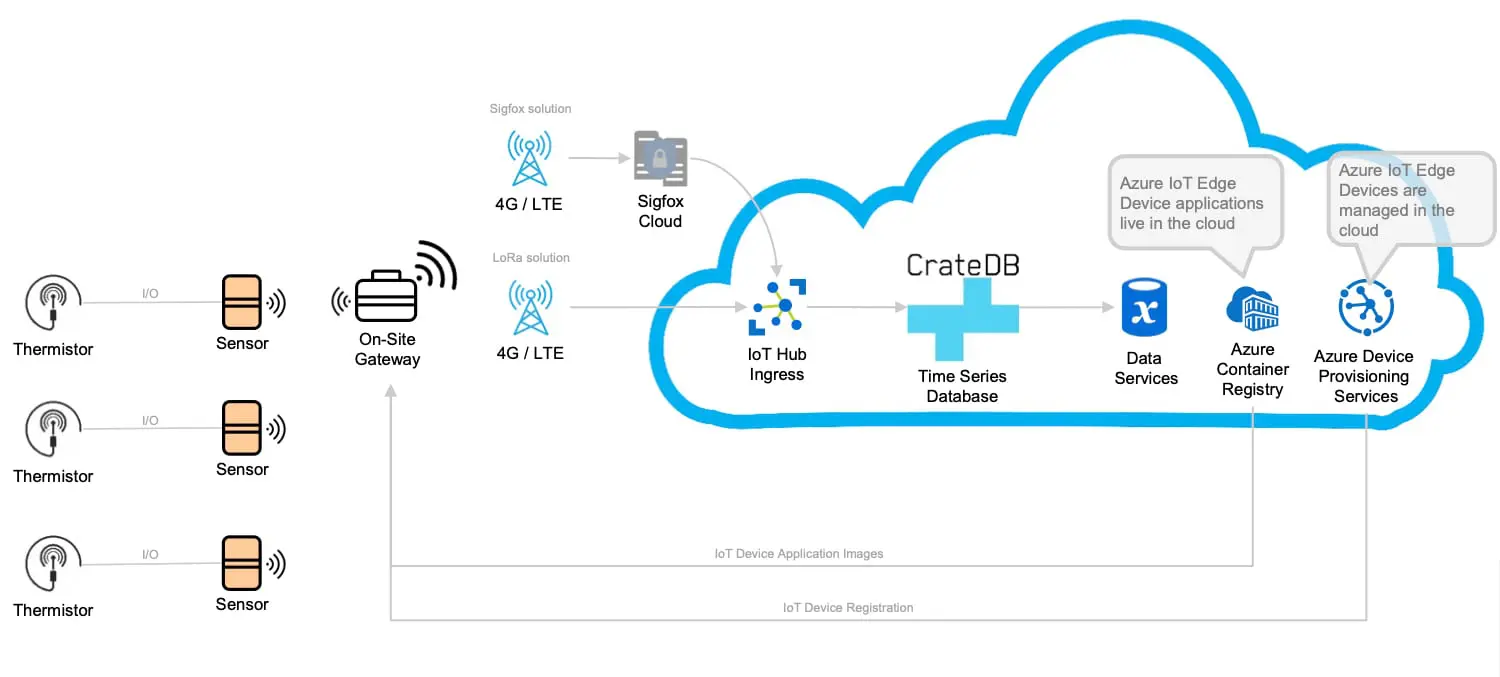
Through our vetting process, we began experimenting with CrateDB, a non-relational and open source time-series database specifically designed for industrial IoT use cases and machine data. As part of our rigorous selection activities, we ended up meeting with a few of the engineers who developed this database. We had them answer a list of detailed technical questions – which we recommend any team should ask when vetting an industrial IoT database.
Through this process, we learned exactly how the database functions under the hood, the underlying technologies it uses, and how processes such as data storage, performance, and fail-over are fulfilled. In the end, the answers to these questions met expectations, and we implemented the database into our proof of concept.
My advice for fellow industrial organizations mapping out their industrial IoT data stack is to remain resolute in seeking this same robust level of assurance in the technologies they’re willing to place at the heart of their solutions.
There is a reason up to 75 per cent of IoT projects fail (according to Cisco research) and why 30 percent don’t even make it out of the proof-of-concept stage (according to Microsoft). Because it is hard to get right without a data layer built for the use case and data type a specific workload calls for. Applying similar rigour in rounding out our data stack has paid dividends toward empowering the customer-facing services we now have in place.
Considering the vast volumes of data that industrial IoT-enabled solutions must handle, the longer a database is running, the harder it is to choose something else. Investing the time to make the right decisions from the beginning is foundational to future success, and will enable you to fill your industrial IoT data stack with appropriately powerful technologies that match the unique needs of your solutions.