

Paul Brebner is Technology Evangelist at Instaclustr. He solves ‘realistic problems’ and builds applications using Apache Cassandra, Spark, Zeppelin, and Kafka. Paul has worked at UNSW, several tech start-ups, CSIRO, UCL (UK), & NICTA.
IoT applications work a heck of a lot better the easier they can collect and process data from a variety of sources and formats. To that end, Apache Kafka – the open source data streaming platform – can be an ideal tool for achieving singular IoT systems that combine heterogenous data sources and sinks. Kafka is also a solid choice for meeting IoT application requirements for hyper-scalability.
The “Kongo problem” is my own invention. It’s an experimental IoT application I came up with as an interesting way (at least in my biased opinion) of learning how to use Kafka with IoT use cases. “Errors” were most certainly made along the way, but I discovered a number of best practices that I’m eager to share.
Here, I’ll cover building a Kafka-based IoT application architecture, a variety of system design approaches, implementation of a Kafka Streams extension, and best practices for optimizing Kafka’s scalability for the IoT.
First things first: let’s get into how Kafka works.
Understanding Apache Kafka
Apache Kafka is a distributed streams processing system, in which distributed producers can send messages to distributed consumers through a Kafka cluster. Kafka meets IoT requirements by providing exceptional horizontal scalability alongside high reliability, high throughput (with zero data loss), and low latency. As an Apache project, it’s also fully open source and comes with particularly strong community support.
Producers and consumers in Kafka’s loosely-coupled publish/subscribe system are not aware of one another. The “filtering” that sorts out how to get the right message to the right consumer is based on topics. It follows a simple logic: producers send messages to topics, consumers subscribe to certain topics and receive the messages sent to those topics when they poll.
The shared concurrency that Kafka utilizes functions a bit like an Amish barn raising. If consumers are in the same consumer group and subscribe to the same topic, they share the work by receiving allocated partitions. Each of these consumers receives messages only from their allocated partitions when polling. If a topic has a higher number of partitions, it can support more consumers, and complete more work – just as more human workers can build a barn faster and bigger.
At the same time, Kafka delivers the same message to multiple consumer groups in order to perform useful broadcasts – functioning like a clone army. Each consumer group gets a copy of each message, duplicating messages across groups. While you’re allowed to use as many consumers as you choose, there are impacts on scalability that I’ll discuss later.
IoT use case: “The Kongo Problem”
Kongo is an ancient name for the Congo river, a key facilitator of trade in its region. When I set my imagination on creating a realistic IoT logistics challenge that could be solved with the help of Kafka, I thought of the river’s vast tributaries and rapid currents, moving water with the same alacrity that Kafka can stream data. From there I came up with the Kongo problem: applying Kafka to build an IoT application that could effectively manage a variety of goods that are 1) stored in warehouses and 2) must be moved safely between them on trucks.
Imagine that each good in this demo IoT operation includes an RFID tag communicating key attributes that we must know in order to store and transport it without damage. Here are a few examples:
- Art – fragile
- Vegetables – perishable, edible
- Chickens – fragile, edible, perishable
- Toxic waste – hazardous, bulky
Our Kafka IoT application will need to perform real-time checks to make sure all transportation adheres to a set of safety rules (for example, we cannot put anything edible in a truck that’s also carrying toxic waste). I did a bit of research into the true-to-life version of these kinds of operations: real transport regulations in my home country of Australia actually identify 97 different goods categories, with a matrix of what goods are allowed to travel together that’s as complicated as you’d expect. Our simulation acts as a worthy microcosm of these very real systems.
For this experiment, we’ll assume that warehouses have the means to safely store any collection of goods. We’ll also say that the RFID tags on each good tell our system whenever a good is loaded or unloaded to or from a truck. And we’ll have each warehouse and truck provide simulated sensor information for variables like temperature, vibration, etc – bringing our total tracked metrics to about 20.
IoT application simulation, and architecture
Now to build a simulation of the Kongo problem. The first step is creating a system that includes all of the goods, warehouses, trucks, metrics, and parameters we require. The simulation then iterates, repeating in a loop to mimic the passage of time and random movement of goods. The simulation also runs a check of colocation data and rules to flag any occurrences where goods should not be transported together.
The basic application follows this flowchart:
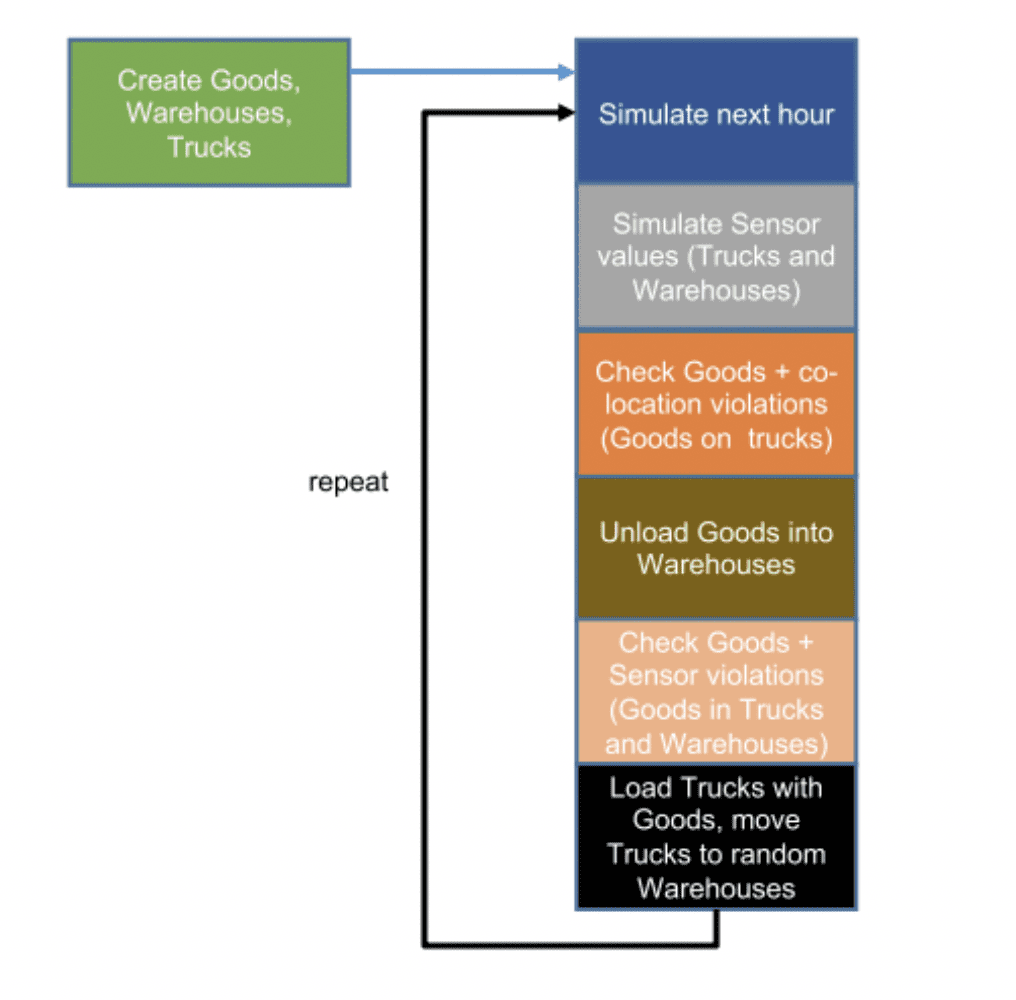
To create the IoT application needed to manage this simulation and protect our operation’s virtual goods, I started from a monolithic architecture design:
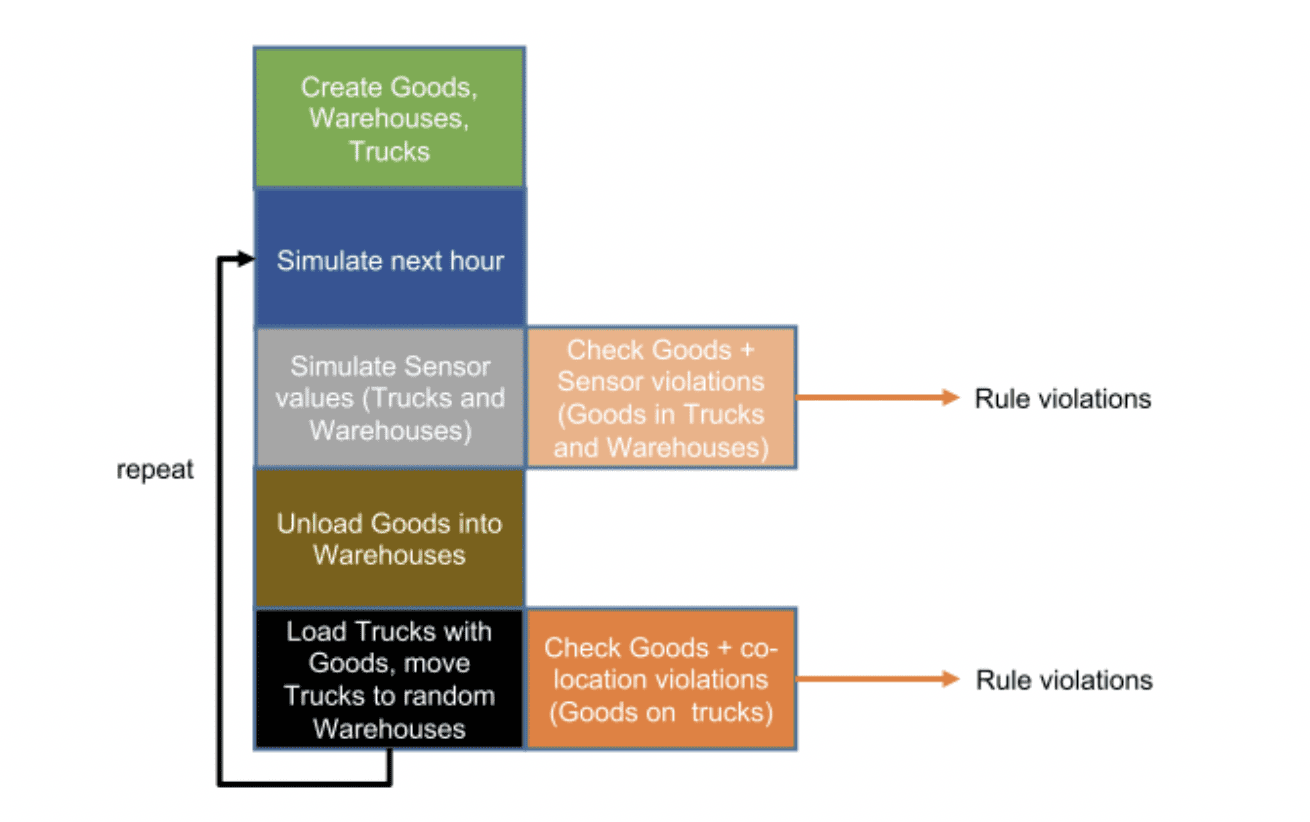
The Kongo problem system operates with perfect knowledge, and creates events that perform rules checks and may produce violations. While this basic architecture functions, it isn’t scalable, and it’s not yet the interesting solution we’re working towards.
To improve the architecture, we use event streams to separate the simulation from the rules checks:
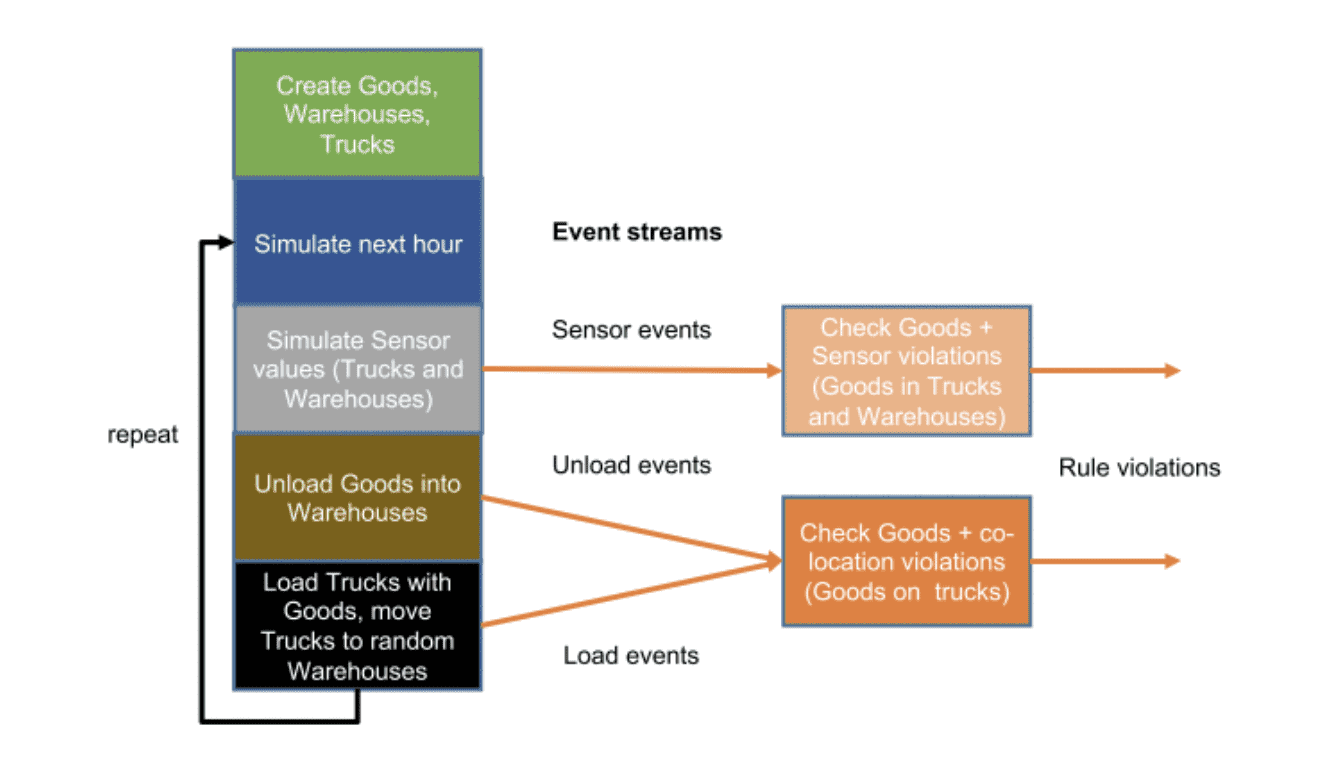
Then we introduce Kafka to provide a true distributed and scalable architecture:
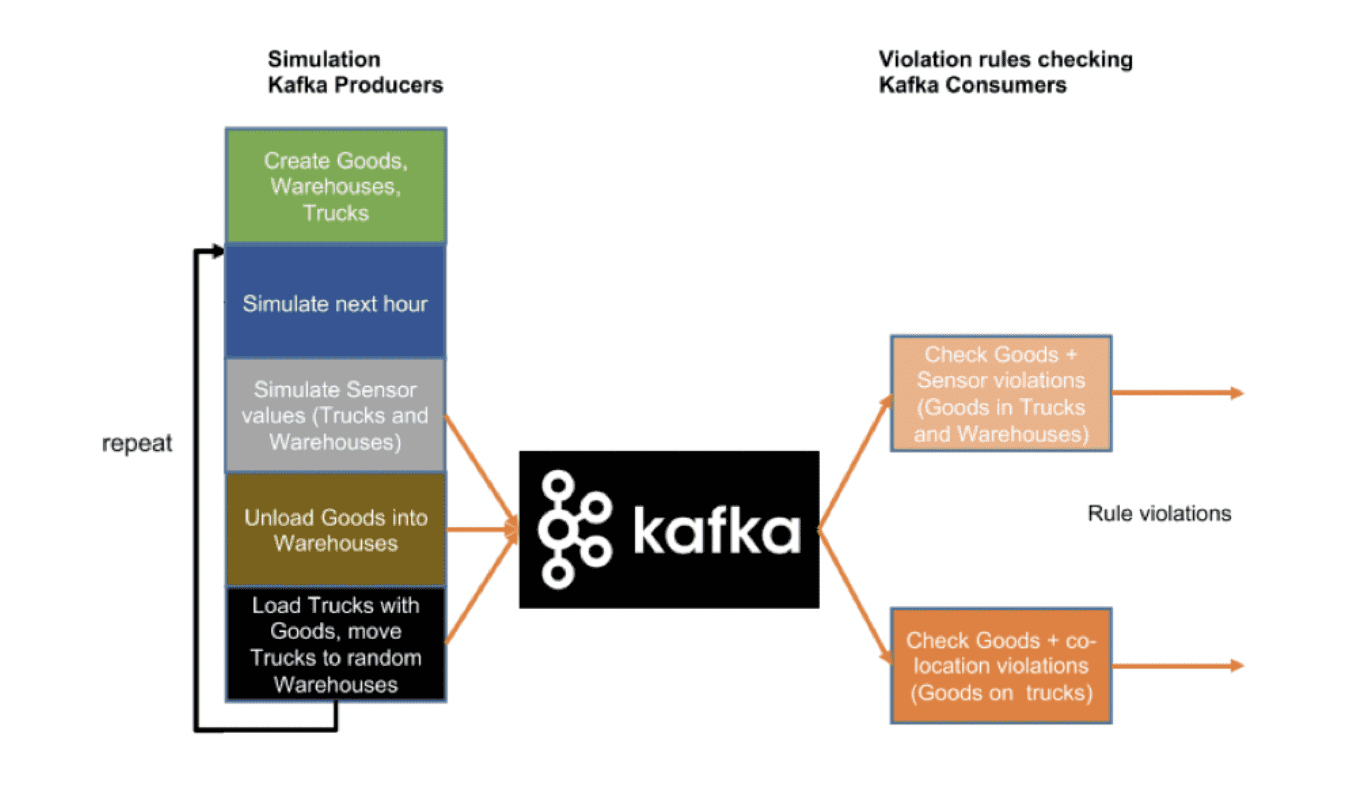
Then we introduce Kafka to provide a true distributed and scalable architecture.
IoT application design decisions
We want the application to be designed such that “delivery events” occur, in which each location (warehouse or truck) delivers events to all the goods present at that location – but not any others.
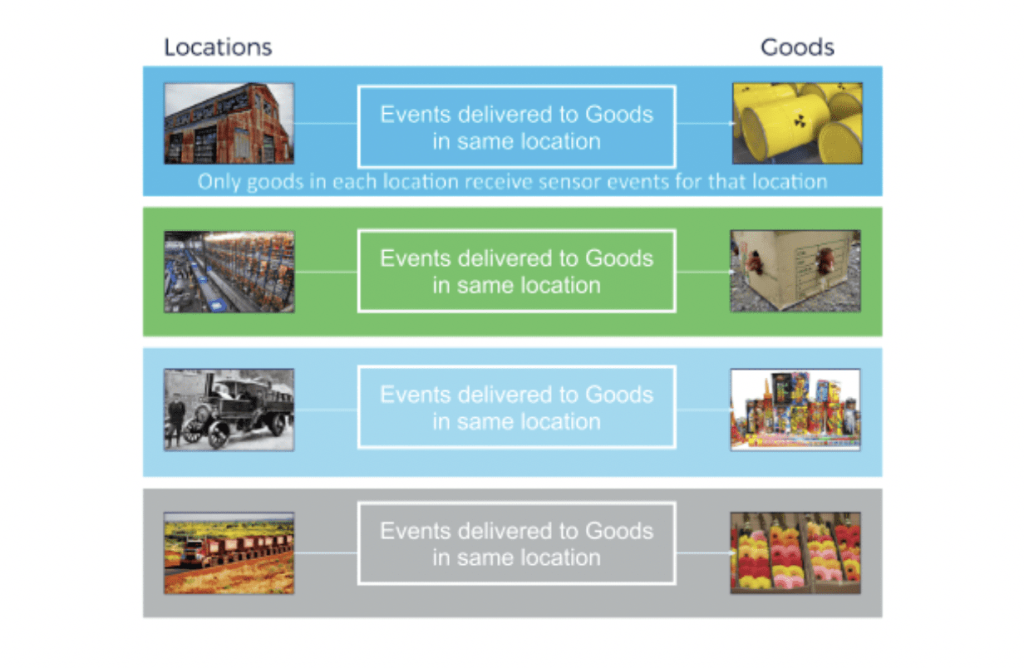
To accomplish this, we want Kafka to guarantee event delivery and make sure that it sends events only to the correct goods. Considering how Kafka makes use of topics to deliver events, it offers two extremes when it comes to fulfilling these needs.
The first option I considered was simply using a single topic to cover every location. The second option was giving each location its own topic. Thinking about how consumers would use topics, I believed that the second option made more sense. Other available design options could decouple goods and consumers, but seemed to add unneeded complexity.
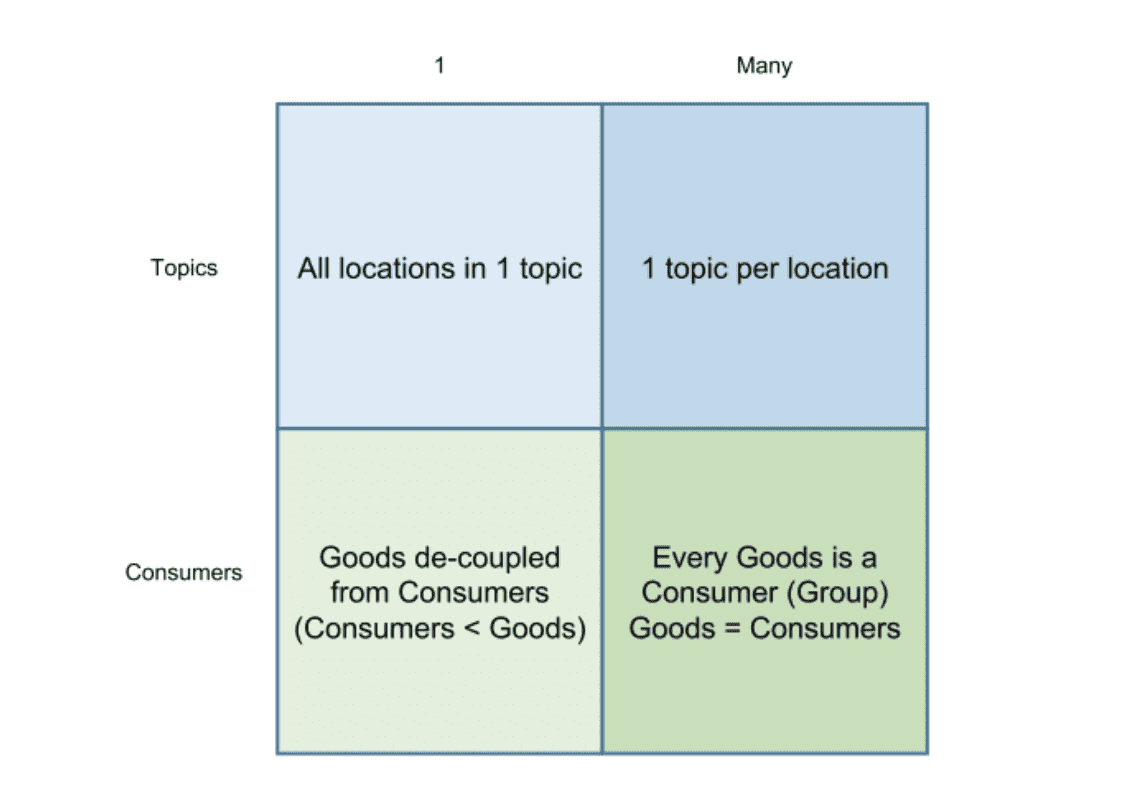
I opted to experiment with the selection in this chart’s lower-right quadrant, making every good a consumer group. Initially this made sense to me, using a number of Kafka consumer groups equal to the number of simulated goods. The experiment’s main achievement turned out to be its educational value, because it taught me that using a high quantity of Kafka topics or consumer groups is actually quite prone to issues.
Here’s a more detailed view of our two design scenarios, followed by the results they deliver.
Design option #1 – Every good is a consumer group
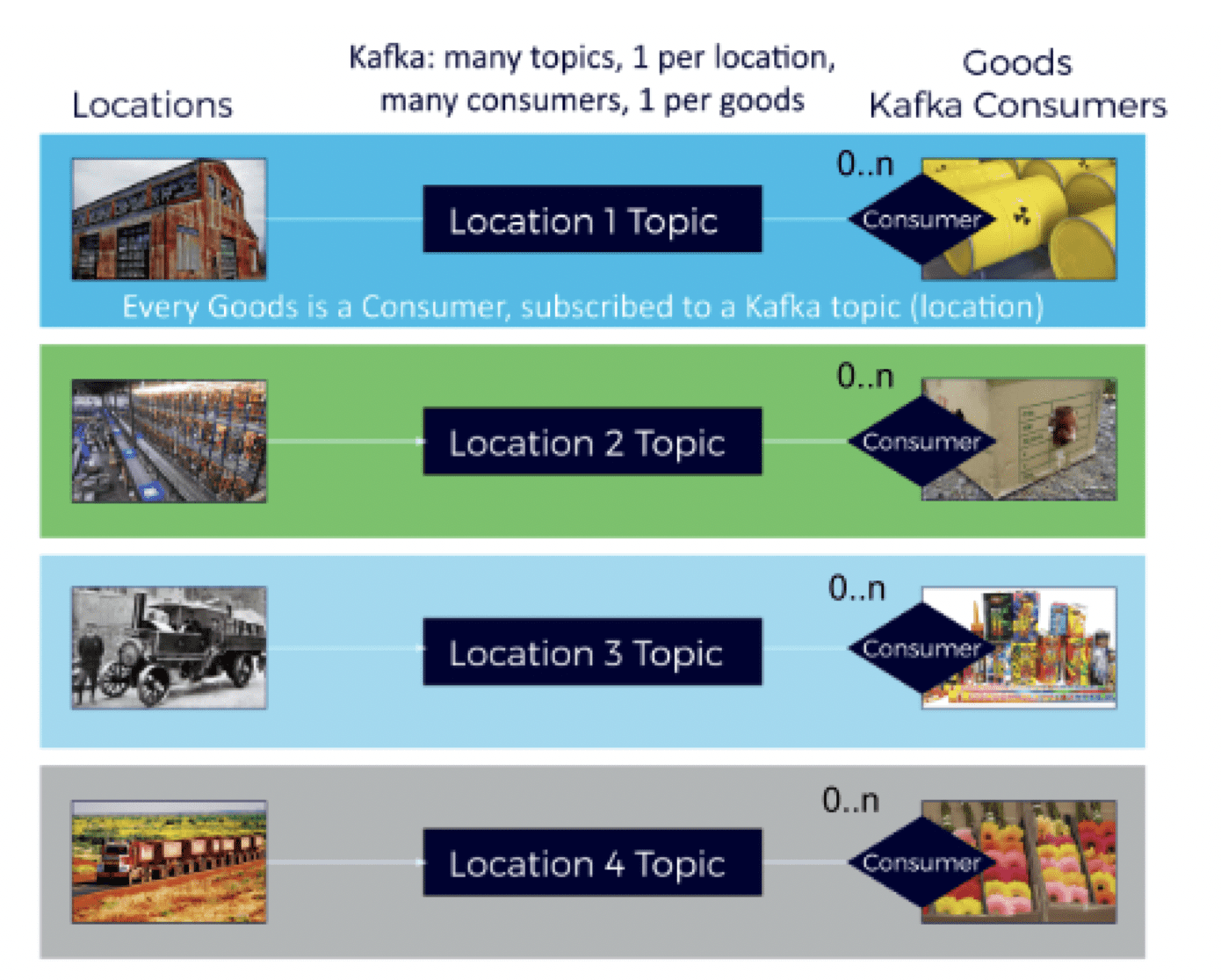
Here the design uses a high quantity of topics and consumer groups, matching the data model in an appealingly-logical way.
Design option #2 – All locations in one topic
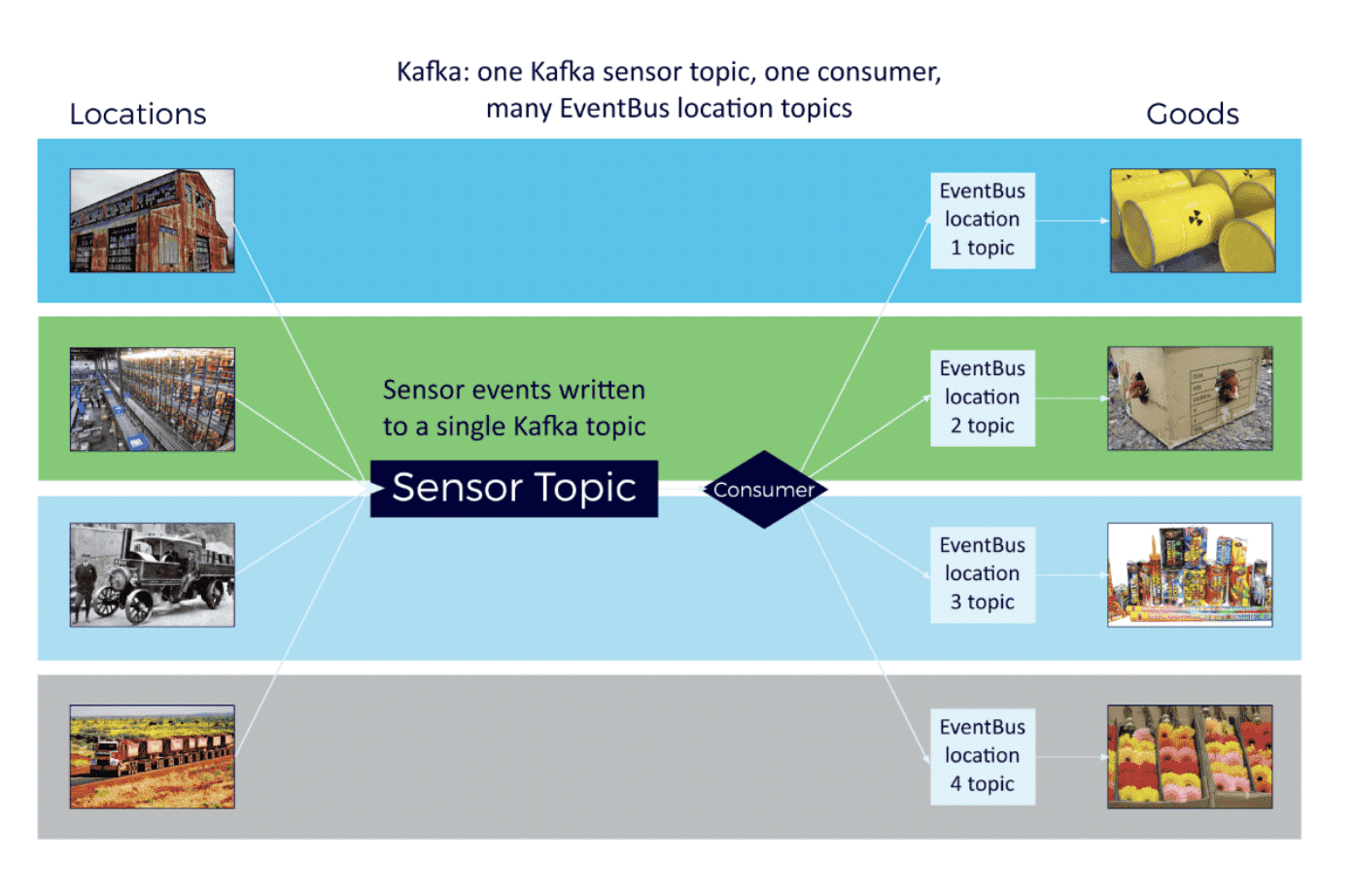
This design seems too simple, with just one topic and consumer group handling all location data. Here an extra logic in the consumers selects what events go to which goods based on their location data, decoupling goods and the system from consumers.
Checking the results
To test out each design, I created a small Kafka cluster and included 100 locations and 100,000 goods moving among them. I evenly spread out the 100,000 goods to the 100 locations using Kafka broadcasting, meaning that each event needed to be delivered to 1,000 consumers.
And here’s what happened:
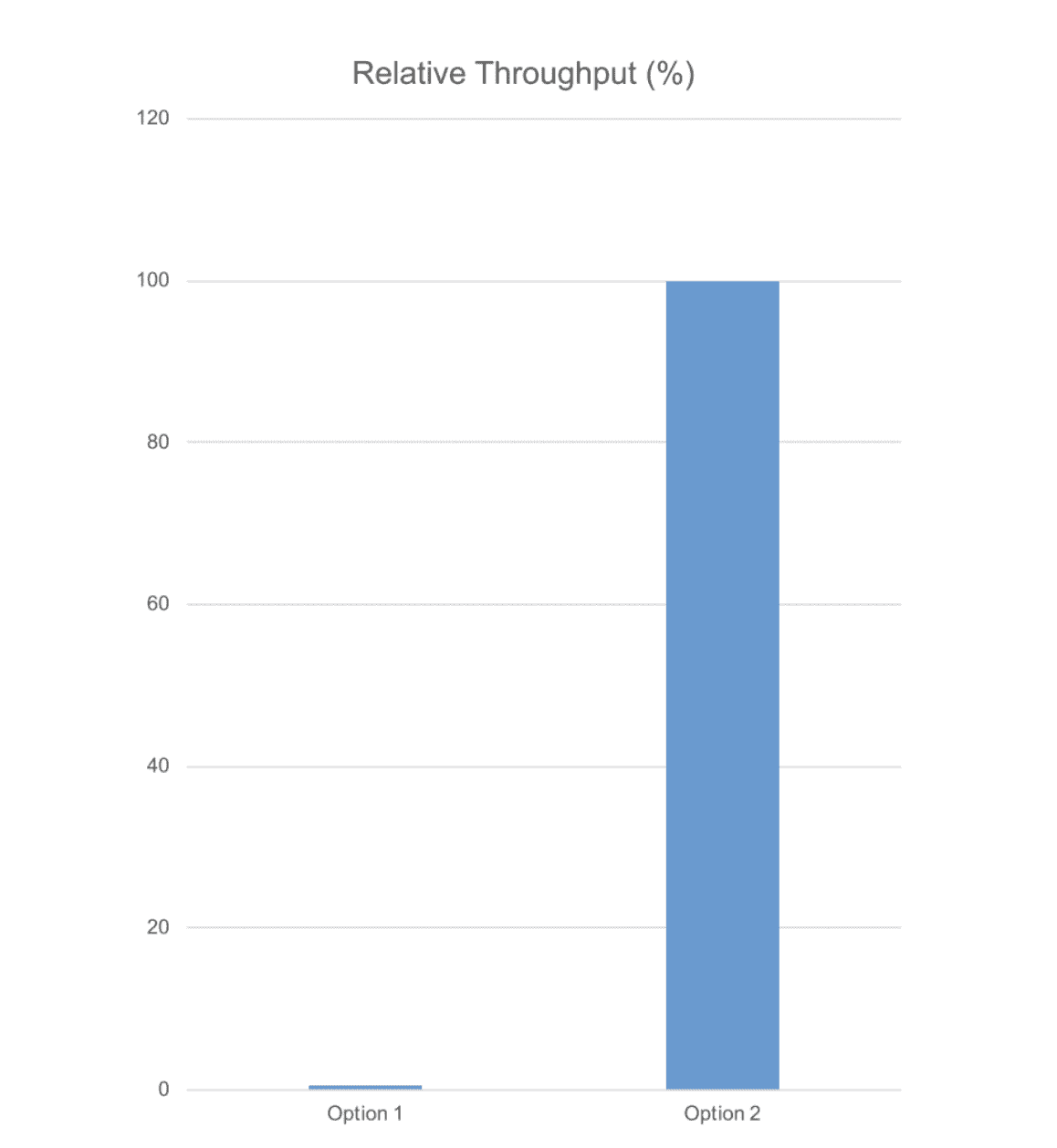
It turns out that all those topics and consumer groups were severely detrimental to our throughput. In contrast, design option #2 with just one topic and consumer group actually was the correct design for optimal throughput. Now we know!
Using Kafka Streams
To explore the possibilities of Kafka Streams – a particularly valuable piece of the Kafka technology stack – I added an extension to the Kongo problem to introduce weight as a property of goods and to check whether trucks are overloaded.
Applications using the Streams API can function as a stream processor. Applications can transform input streams to output streams, consuming an input stream from one or more topics and producing an output stream that reaches one or more topics. To get started with Kafka Streams, I recommend using the available Kafka Streams DSL that offers built-in stream and table abstractions, and lets users leverage a declarative functional programming style.
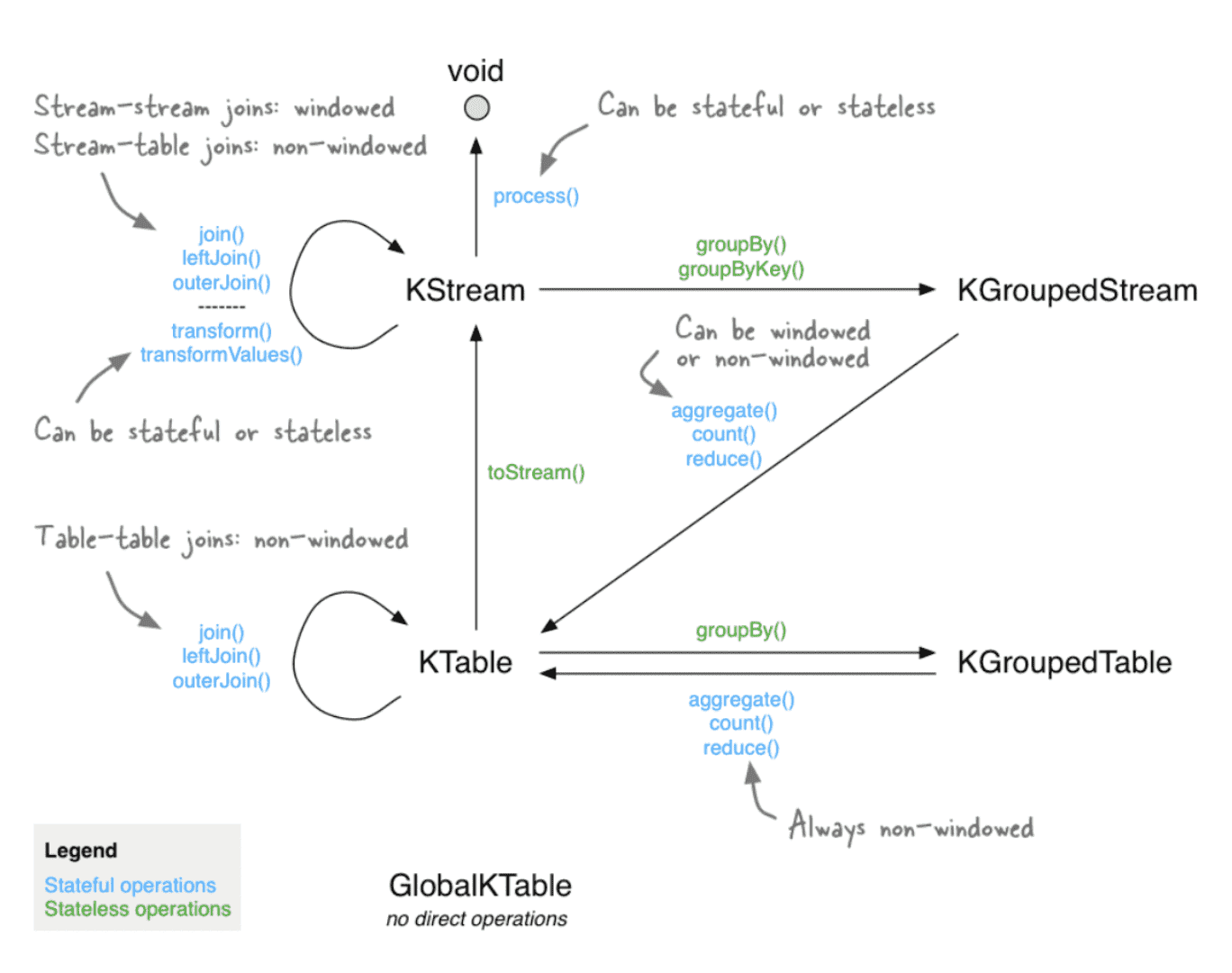
Kafka Streams enables two kinds of stream transformations: stateless transformations such as map and filter operations, and stateful transformations like aggregations (including count reduced joins and windowing). The following diagram shows a state machine explaining what operations work together, every operation types’ produced output, and the uses you can put those outputs to. As a new user, this diagram was essential to understanding how to get a Kafka Streams project off the ground.
 To build my Streams application extension, I added weight values for every good in the simulation, as well as load limits for trucks. With that groundwork complete, I then created a Streams application that checked for truck overloads.
To build my Streams application extension, I added weight values for every good in the simulation, as well as load limits for trucks. With that groundwork complete, I then created a Streams application that checked for truck overloads.
These initial forays into Kafka Streams ran up against two challenges: 1) I received lots of Streams topology exceptions, and 2) some trucks were registering negative weight values. I’d accidentally created flying trucks!
I soon learned that Streams have processor topologies, and that they involve a fair bit of complexity. A third-party tool let me visualize my solution’s topology and was valuable in helping me understand and debug my issues – especially considering that I initially didn’t know what the issues meant. As an example, the visualization diagram below made it clear that I was breaking a rule by using the same node as the source for two different operations:
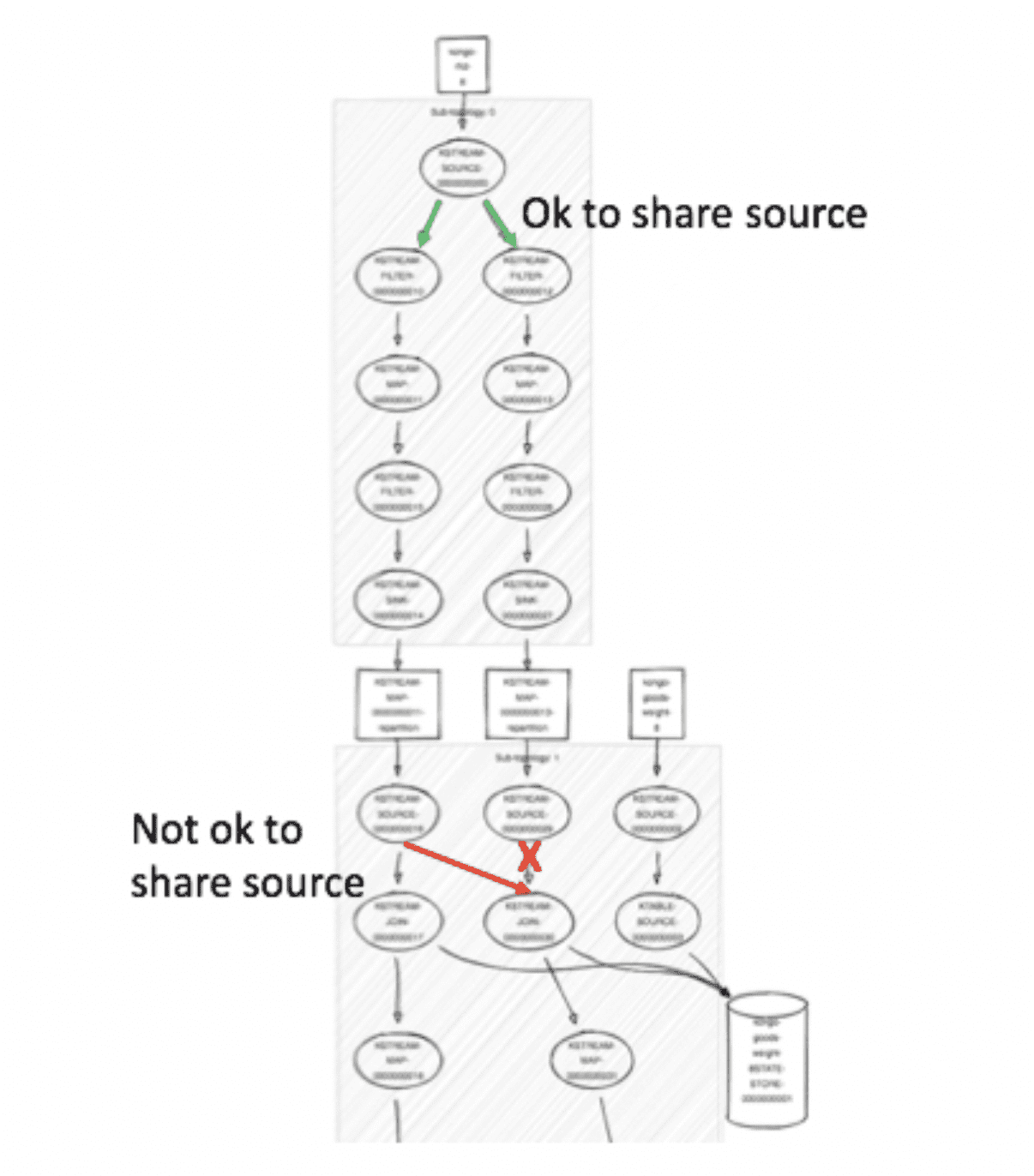
To get my negative-weight trucks down from the sky, I had to learn not to rely on Kafka’s default settings. I turned on the “exactly-once” transactional setting, telling the transactional producer to let my IoT application send messages to more than one partition in an atomic manner. Suddenly, my trucks and the logic of weights within my simulation were brought back down to earth.
Scalability best practices
Lastly, I performed a variety of scalability tests to learn how best to scale this and other Kafka-based IoT applications.
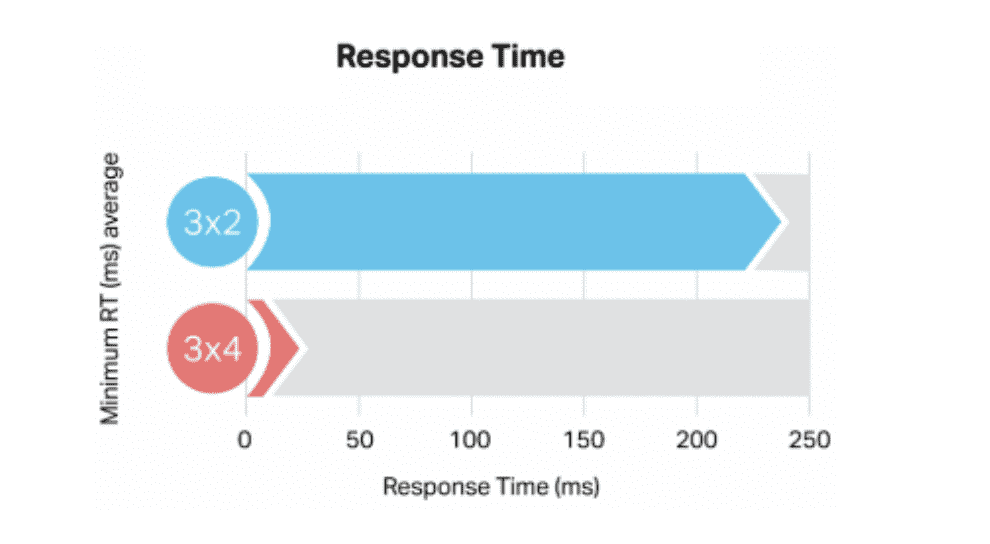
I used a simulation including 10,000 goods, 100 warehouses, and 200 trucks, and ran a series of experiments: scaling to three nodes with two cores each (3×2), six nodes with two cores each (6×2), a 6×2+3x2 multiple cluster scenario, and a three-nodes-with-four-cores-each (3×4) cluster.
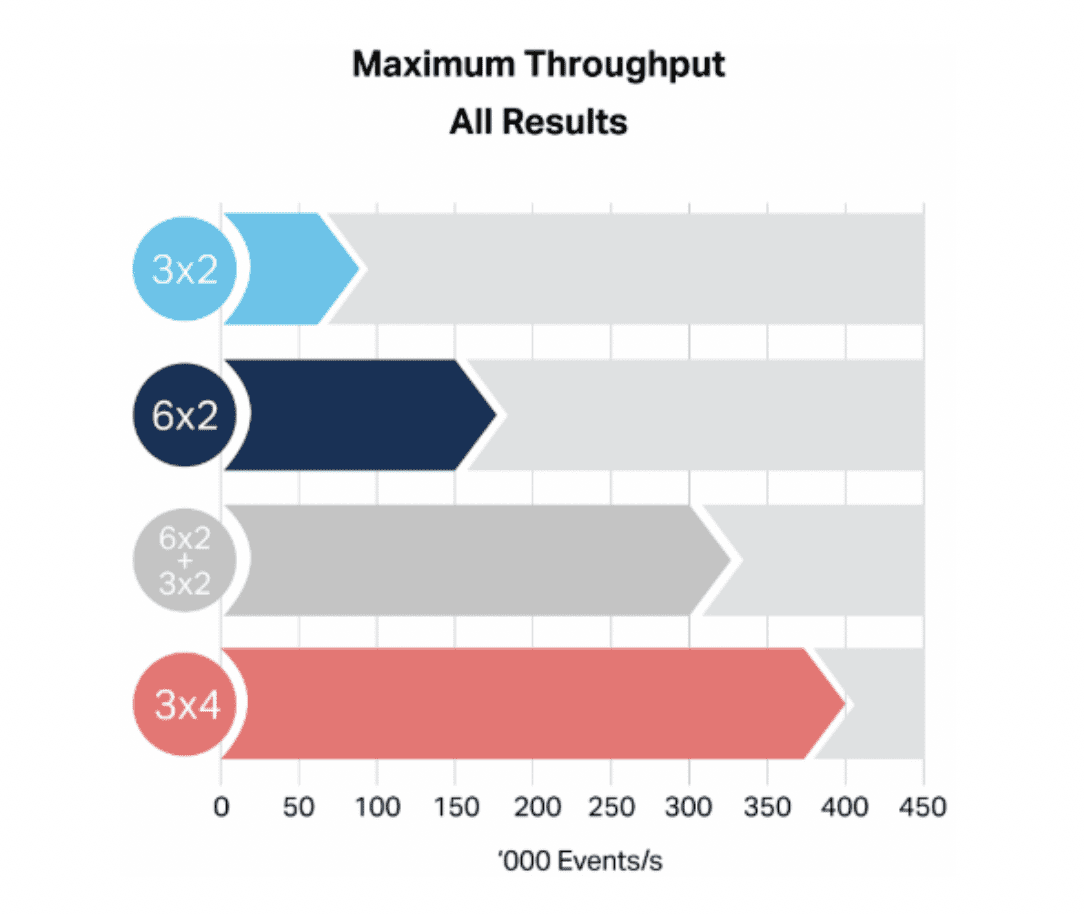
First of all, the results show that this demo IoT application has very nice scalability. It’s important to note that these are small clusters, and that in production you’d be able to scale every bit as far as you need. One lesson for large-scale Kafka users: you can split your IoT application to put different topics on different Kafka clusters and scale them independently, which can be a useful trick across multiple IoT locations.
Another important note is that larger instances deliver huge performance improvements, probably thanks to the greater network speeds allocated to them by providers like AWS. If your Kafka IoT application needed lower latency, try a bigger instance:
Avoiding hashing collisions
I did hit one complicated issue during these scaling experiments: hashing collisions. These created an exception that said there were too many open files. It turns out that a Kafka consumer will actually time out if it doesn’t receive any events over a given time period. And when those consumers timed out, my system automatically replaced them with new ones…until it reached a breaking point.
The simulation included 300 locations, 300 partitions, and 200 unique values. In practice, that meant 200 of the 300 consumers received events, and the rest timed out from hashing collisions. And when a partition received more than one location value, others wouldn’t get any. This led to the realization that the number of keys in Kafka has to be far larger than the number of partitions. As a best practice, I recommend going 20 times larger. Another rule: the number of partitions needs to be equal to or greater than the number of consumers in a group.
There’s a fine balance. Too many consumers will hurt Kafka scalability. But if consumers are slow to read and process events then more consumer threads and more partitions become necessary, impacting scalability just the same. The right approach is reducing consumer response times as much as possible.
Leveraging Kafka consumers only to read events from the Kafka cluster will optimize scalability. Use a separate thread pool or another scalable solution to asynchronously process any database writing or run complex checks or algorithms. It’s true that Kafka is an immensely simple-to-scale solution for your IoT application needs, but that’s most true when you’re using as few consumers as you can!